A few years ago, Wine Folly published a very nice subway-style infographic that characterizes aspects of wine reviews into twelve categories: body, yeast, style, tannin, acidity, alcohol, spice, fruit, flower, herb, oak, and inorganic. I was curious to know whether unsupervised machine learning could learn to create clusters of semantically similar terms. For instance, could it learn that plum and cherry or tight and flabby are terms used in similar linguistic contexts?
I used a standard deep learning technique (word2vec) to learn how wine descriptors were used in these reviews and a popular dimensional reduction and visualization technique (t-SNE) to illustrate the semantic association among those terms. Machine learning did indeed learn to make sensible clusters and associations, although nowhere near the idealized structure and clarity of wine folly’s scheme.
The data set: I took more than 157,000 wine reviews from Wine Spectator, Wine Enthusiast Magazine, and a US online wine merchant and prepared them for natural language processing. Reviews were switched to lower case and punctuation and english stopwords were removed. I then used a WordNet Lemmatizer to introduce some standardization. (Lemmatizers convert words to a single canonical version; for instance, plurals are converted to their singular version, bottles → bottle.) However, I deliberately did not use a stemmer, which is a more common operator, as I wanted the output terms to be readable. (Stemmers are more aggressive than lemmatizers and remove word endings to leave a stem. While some stemmed words are still english words, many are not, such as delicious → delici.)
As the final step of processing, these 150k reviews were concatenated into a single list of ~8 million words such as
chateau
st
jean
one
sonoma
county
acclaimed
winery
produce
…
ripe
full
palate
super
fresh
chalky
wealth…
With stopwords and punctuation removed, this stream is no longer english but instead is a concentration of terms in which the associations among the key terms is maintained.
The model: I used word2vec to learn the embeddings. This is a high dimensional representation of words or symbols so that terms that are used similarly―e.g. “tangerine” and “grapefruit” which are both citrus descriptors―are close to each other in that space. In other words, it learns the context of words. I then used a dimensional reduction technique called t-SNE to project those embeddings into two dimensions.
I used Tensorflow’s word2vec basic example which took about 10 minutes to train on a Macbook Air with just 8Gb RAM. While I experimented with a number of the parameters, I ended up using all of their defaults. That example code ends with a t-SNE visualization. Again, while I experimented with the parameters, I ended up using the default perplexity = 30. (There is a nice visual overview of the effect of the perplexity parameter from the Google Brain team here.) The results: the plot above shows the final visualization plotting 600 terms. As can be seen in this high-level view, it is not highly clustered. This was true scanning across the range of perplexity values. However, if we zoom in, we find that it captured many interesting associations.
The results: the plot above shows the final visualization plotting 600 terms. As can be seen in this high-level view, it is not highly clustered. This was true scanning across the range of perplexity values. However, if we zoom in, we find that it captured many interesting associations.
First, there are several clusters of numbers. One cluster contains 1–14, another 15–100. Interestingly, there are two clusters of years. One contains 2001–2014 thus capturing the past vintage of the wine; in fact vintage and release are both adjacent to that group. Another cluster contains 2015–2025 and so captures future dates of when the wine should be stored or drunk.
In another area, we find a set of common descriptors. In the top right, we find citrus descriptors (nectarine, grapefruit, lemon, lime etc). Nearby are flowery and herbaceous terms: lavender, rose, herb, flower, violet. To the left are dark berries: blackberry, cassis, plum, and cherry. Below are coffee, chocolate and more earthy terms such as mocha, espresso, chocolate, tobacco, leather, and smoke.

In other areas, profile, nose, aromatics, aroma and scent are adjacent terms.
Below, we find terms that describe the character and feel of the wine. At right, we have terms such as crisp, light, and bright. Left of center we have bold, intense, and dense. Elsewhere polished, balanced, and silky.

The figure is peppered with these sensible and reasonable associations although it is interspersed with associations that are not meaningful or obvious. It does manage to capture some aspects of the clusters from the Wine Folly chart, such as subsets of their fruit, spice, acidity, and flower groups, often in detail. This is crudely illustrated below, where pink maps to Wine Folly’s categories and blue represents other groupings. 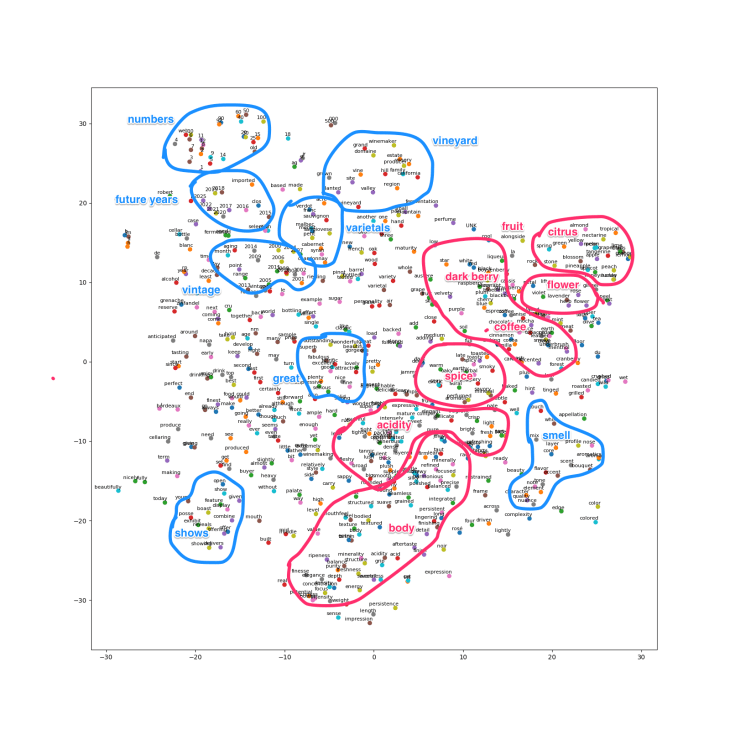 It even managed to associate enjoy and drinking. Who can argue with that?
It even managed to associate enjoy and drinking. Who can argue with that?

I don’t know about you but I find this model fairly impressive from 10 minutes training on an underpowered laptop with just a 2 layer network.
Cheers!
